Change data capture (CDC) is the process of capturing changes made at the data source and applying them throughout the Data Warehouse. Since capturing and preserving the state of data across time is one of the core functions of a data warehouse, a change data capture framework has a very important role in ETL design for Data Warehouses. Change Data Capture can be set up on different ways based on Timestamps on rows, Version Numbers on rows, Status indicators on rows etc. Here we will be building our framework based on "Timestamps on rows" approach.
In one of the our early articles, we spoke about operational meta data logging framework. Lets add on to that and build our Change Data Capture framework. We will be leveraging the capabilities provided by Informatica PowerCenter to build our framework.
Framework Components
Our Framework for Change Data Capture will include below components.
- A Relational Table :- To store the meta data.
- Mapping, Workflow variables : Variables to store and process latest timestamp of processed records.
- A Reusable Expression :- A reusable expression transformation to find latest timestamp of processed records.
- Pre, Post Session Command Task :- Command task to collect the meta data.
- Reusable Worklet :- Worklet to log the data load details into the relational table.
1. Relational Table
A relation table will be used to store the operational data with the below structure. Data in this table will be retained for historical analysis.- ETL_JOB_NAME : ETL job name or Session name.
- ETL_RUN_DATE : ETL job execution date.
- DATA_START_TIME : Least timestamp of processed records
- DATA_END_TIME : Latest timestamp of processed records
- SRC_TABLE : Source table used in the ETL job.
- TGT_TABLE : Target table used in the ETL job.
- ETL_START_TIME : ETL job execution start timestamp.
- ETL_END_TIME : ETL job execution end timestamp.
- SRC_RECORD_COUNT : Number of records read from source.
- INS_RECORD_COUNT : Number of records inserted into target.
- UPD_RECORD_COUNT : Number of records updated in target.
- ERR_RECORD_COUNT : Number of records error out in target.
- ETL_STATUS : ETL Job status, SUCCESS or FAILURE.
- ETL_CREATE_TIME : Record create timestamp.
- ETL_UPDATE_TIME : Record update timestamp.
2. Mapping and Workflow Variables
Two mapping variables will be used to capture the least and latest timestamp of the records processed through each data load. These variables hold the time frame of the data processed.
- $$M_DATA_START_TIME as Date/Time
- $$M_DATA_END_TIME as Date/Time
Additionally two workflow variables will be used to capture the least and latest timestamp of the records processed through each data load. These variables hold the time frame of the data processed.
- $$WF_DATA_START_TIME as Date/Time
- $$WF_DATA_END_TIME as Date/Time
Note : Usage of these variables are described in the implementation Steps.
3. Reusable Expression
A reusable expression will be used to capture the least and latest timestamp of the records processed through each data load.
This expression takes the timestamp column as the input based on which Change Data Capture is setup. This expression transformation will find and assign the values to the mapping variables described above.
This expression takes the timestamp column as the input based on which Change Data Capture is setup. This expression transformation will find and assign the values to the mapping variables described above.
Below is the expression used in the transformation and the structure of the Reusable Expression Transformation.
- SETMINVARIABLE($$M_DATA_START_TIME,DATA_TIME)
- SETMAXVARIABLE($$M_DATA_END_TIME,DATA_TIME)

4. Pre and Post Session Command Task
Pre and Post session command task will be used to generate a comma delimited file with session run details. This file will be stored into $PMSourceFileDir\ directory with a name $PMWorkflowName_stat.txt.
Note :
- $PMSourceFileDir, $PMWorkflowName are the session parameter, which gives the source file directory and name of workflow.
- File name generated will always be <WorkflowName>_stat.txt
The comma delimited file will have the structure as below.
- ETL Start time
- ETL End time
- ETL Job name
- Source table name
- Target table name
- Source record count
- Records inserted count
- Records updated count
- Error record count
- ETL Job status
- $PMSessionName : Name of the Informatica session.
- $PMSourceName@TableName : Name of the source table name.
- $PMTargetName@TableName : Name of the source table name.
- $PMSourceQualifierName@numAffectedRows : Number of records returned from source.
- $PMTargetName@numAffectedRows : Number of record inserted/updated into the target table.
- $PMTargetName@numRejectedRows : Number of records error out in target.
Note : SourceName, TargetName, SourceQualifierName will be replaced by corresponding transformation instance name used in the mapping.
Pre Session Command Task
Pre session command task will be used to create the file with the session start time stamp.echo %DATE:~10,4%-%DATE:~4,2%-%DATE:~7,2% %TIME:~0,2%:%TIME:~3,2%:%TIME:~6,2%,
> $PMSourceFileDir\$PMWorkflowName_stat.txt
Post Session Success Command Task
Post session success command task will be used to append the file, which is created in the pre session command with session run details. This will capture the SUCCESS status along with other session run details.echo %DATE:~10,4%-%DATE:~4,2%-%DATE:~7,2% %TIME:~0,2%:%TIME:~3,2%:%TIME:~6,2%,
$PMSessionName,
$PMSTG_CUSTOMER_MASTER@TableName,
$PMINS_CUSTOMER_MASTER@TableName,
$PMSQ_STG_CUSTOMER_MASTER@numAffectedRows,
$PMINS_CUSTOMER_MASTER@numAffectedRows,
$PMUPD_CUSTOMER_MASTER@numAffectedRows,
$PMINS_CUSTOMER_MASTER@numRejectedRows,
SUCCESS,
>> $PMSourceFileDir\$PMWorkflowName_stat.txt
Post Session Failure Command Task
Post session failure command task will be used to append the file, which is created in the pre session command with session run details. This will capture the FAILURE status along with other session run details.
echo %DATE:~10,4%-%DATE:~4,2%-%DATE:~7,2% %TIME:~0,2%:%TIME:~3,2%:%TIME:~6,2%,
$PMSessionName,
$PMSTG_CUSTOMER_MASTER@TableName,
$PMINS_CUSTOMER_MASTER@TableName,
$PMSQ_STG_CUSTOMER_MASTER@numAffectedRows,
$PMINS_CUSTOMER_MASTER@numAffectedRows,
$PMUPD_CUSTOMER_MASTER@numAffectedRows,
$PMINS_CUSTOMER_MASTER@numRejectedRows,
FAILURE,
>> $PMSourceFileDir\$PMWorkflowName_stat.txt
Note :
- Pre, Post session commands need to be changed based on Informatica server operating system.
- Highlighted part of the script need to be change based on the source, target table instance name used in the mapping.
5. Reusable Worklet
A worklet will be created to read data from the comma delimited file generated by the pre, post session command task. In addition to the data read from the comma delimited file, the worklet takes Data Start Time and Data End Time as input parameters. Data Start Time and Data End Time is the time frame of the data processed records
Reusable Mapping
A reusable mapping will be created to read data from the comma delimited file generated by the pre and post session command task.
This mapping takes two input parameters, Create the mapping and add two mapping variables in the mapping as shown below.
- $$M_DATA_START_TIME as Date/Time
- $$M_DATA_END_TIME as Date/Time
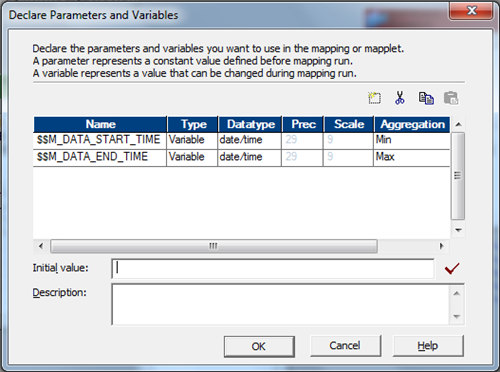
This mapping reads data from the file generated by the Pre, Post session command task. Mapping will include an expression transformation to generate the data elements required in the target table, with below OUTPUT ports, This expression transformation takes two input ports from the source file.
- ETL_RUN_DATE :- TRUNC(SESSSTARTTIME)
- DATA_START_TIME :- $$M_DATA_START_TIME
- DATA_END_TIME :- $$M_DATA_END_TIME
- ETL_CREATE_TIME :- SESSSTARTTIME
- ETL_UPDATE_TIME :- SESSSTARTTIME
- O_ETL_START_TIME :- TO_DATE(LTRIM(RTRIM(ETL_START_TIME)),'YYYY-MM-DD HH24:MI:SS')
- O_ETL_END_TIME :- TO_DATE(LTRIM(RTRIM(ETL_END_TIME)),'YYYY-MM-DD HH24:MI:SS')

Below is the complete mapping structure, created to populate target table 'ETL_PROCESS_STAT'

Reusable Worklet
Reusable worklet is created based on the mapping created in the last step. Create the worklet and add two worklet variables.
- $$WL_DATA_START_TIME as Date/Time
- $$WL_DATA_END_TIME as Date/Time

Now create the session in the worklet, which will be configured to read data from the file created by the pre, post session command as shown below. This session is based on the reusable mapping created in the previous step.
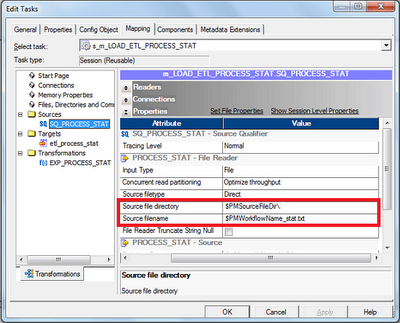
Note : Make sure the Source File Directory and Source File name are given correctly based on the file generated by pre/post session command
Assign the worklet variables to the mapping variables as shown below, using the pre-session variable assignment option in the components tab.
With that we are done with the configuration required for the worklet.


Framework implementation in a workflow
Now lets see how we implement the Change Data Capture Frame work in a mapping.
Mapping
Lets start the mapping creation and add two mapping variables as shown below.
- $$M_DATA_START_TIME as Date/Time , Initial Value 12/31/2050 00:00:00.000000000
- $$M_DATA_END_TIME as Date/Time , Initial Value 12/31/2050 00:00:00.000000000
Note : Give the initial value for both the variables

Add source and source qualifier to the designer work space, open the source qualifier and give the filter condition to get the latest data from the source.
- STG_CUSTOMER_MASTER.UPDATE_TS > CONVERT(DATETIME,'$$M_DATA_END_TIME')
Hint : Use the column in the filter condition, based on which the Change Data Capture is built up on.

Add the Reusable Transformation 'EXP_CDC_TIMESTAMP' to the mapping and map the column 'UPDATE_TS' from the source qualifier to the input port of the expression.
Hint : Use the column from the source qualifier, based on which Change Data Capture is built on.
Note : The reusable transformation will find the least and latest timestamp and will store in the mapping variables, which can be used in the subsequent runs.

Map the DUMMY column from 'EXP_CDC_TIMESTAMP' to the down stream transformation and complete all other transformation required in the mapping.
Workflow
Once the mapping is complete. lets create the workflow and add two workflow variables as shown below.
- $$WF_DATA_START_TIME as Date/Time
- $$WF_DATA_END_TIME as Date/Time

Create the session in the workflow and add the Pre, Post session commands, which creates the flat file with the session run details.

Now map the mapping variables to the workflow variables as below.


With that we are done with the configuration. And below is the structure of the completed workflow, with Change Data Capture Framework.















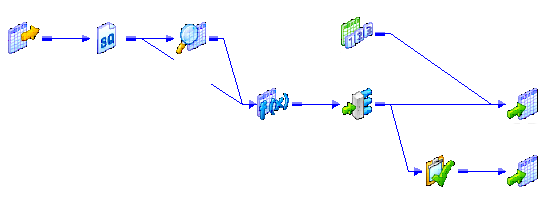



















{kind=link}
{kind=link}
{kind=link}